Introducing Time Dilation (TiDi)
It's often said that the War on Lag cannot be won because our players can always bring one more ship. This is fundamentally true, and embracing that truth is important to the work we do here on Team Gridlock. In addition to the optimization work we do, we also aim to attack degradation issues, so that when the server does become overloaded, it's handled in a reasonable fashion. That's what this blog is about today. But, to understand where we're going, it helps to know where we are. Currently when a server is overloaded, there is no explicit mechanism for dealing with the situation. The same mechanisms that drive normal operations keep on rolling in their own way. Some interesting behaviors come of that, but I'll need to define some terms before I get too deep into that.
Of Tasklets, Schedulers and Yielding
The EVE Online servers, fundamentally, exist to run a set of tasks - be they responding to an incoming packet from a client or a task that maintains the state of modules or, well, nearly everything. They're called tasklets for reasons that you don't need to know today. But since we're dealing with a computer here, only one tasklet can be running at any given time and some piece of software needs to exist to decide which tasklet that should be. That's called a scheduler.
Schedulers come in many different styles and flavors. The one that runs EVE Online's tasklets is quite simple - it's a round-robin, cooperatively-multitasking scheduler. Being round-robin simply means that every tasklet will be given a chance to run before any tasklet is given two chances. There's no prioritization or special treatment here - it's very fair in that sense; everyone gets a turn. Cooperative multitasking means that no tasklet will be externally interrupted during its course of execution. A tasklet will run until it either completes or runs a special routine that signals to the scheduler that it would like to let everyone else have a turn now. That's called yielding.
So what we have is a system like so:
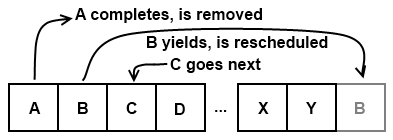
You might be asking yourself, "Why would a tasklet ever yield?" Well, if they were selfish they wouldn't, they would hold on for dear life and get everything they want done completed before letting any of those other, obviously less important slobs have a go. But that does not work out well...starving everyone out of CPU resources is pretty much a bad idea for all involved. Because of that, when we're writing systems in code and expect that an operation might take a long time to execute, we'll put yields in there at convenient points so it behaves well with others.
The other common reason a tasklet will yield is if it's waiting for some input from another machine, like the database. There's no sense sitting there constantly asking "is it back yet?" over and over and over - we can let other tasklets do their business while we wait. (Yes tech guys, it's a suspended state which is signaled on I/O completion, but they don't need to know that.)
Yeah dude, where are you going with all this?
Sorry, I like to write about computer science-y stuff. Where this is going is explaining the main way in which tasklets behave under heavy load. When the server is overloaded, it can take upwards of five seconds or more to get another turn at doing stuff after you've yielded. The upshot of all of this is that tasks that are either very nice or have lots of communication requirements can end up taking a whole hell of a long time to complete as they spend most of their time waiting for a turn to execute. Ship death is a great example of this - it takes many round trips to the database, so yields very frequently, causing the event to stretch over many minutes before finally completing. Similarly, modules can get very far behind in processing because the tasklet that manages them yields after 100 milliseconds of execution.
I tell you all of this in order to motivate this next statement:
The EVE Online server should degrade in such a way that the queue of tasklets waiting for execution is minimized - ideally zero.
That's precisely what Time Dilation aims to do.
In order to bring things down to the level where the server can keep up, there's painfully few options. They boil down to two: reduce load or increase processing capacity.
Gridlock has been spending a lot of our time to date reducing load via optimization. We can go further on this path - and very likely will - but we're at a point where a lot of the easy wins are behind us. Going multi-threaded falls into the increasing capacity category - it increases how much load can be processed per second, but never as much as most people think. We'll get there some day 'cause, well, we'll have to, but for today it's way more work for the benefit we'd see from it to be worth attacking.
Throttling load is a much more compelling proposition at this point, now that we've cleared out a pile of easy optimizations. A few different proposals on what we could do here have been put forward. The one most people jump to first is to have Destiny, our physics simulation, update at a lower resolution than once per second as we get overloaded. That would help lower the load of doing the actual simulation, but it turns out that only accounts for 5-10% of the load, so it wouldn't buy us much.
Another common idea is to increase module cycle times but increase their effectiveness and cost proportionally. This would buy us more in the way of headroom, but changes the design of the game very deeply depending on how much load there is. That's very clearly not cool. The current degradation scheme also changes game mechanic behavior, and we'd like to move away from that instead of making it worse.
Thankfully we do have a means to throttle load that buys us a lot while leaving the design intact: make time run slower. A large majority of the load in large engagements is tied to the clock - modules, physics, travel, warpouts, all of these things happen over a time period, so spacing out time will lower their load impact proportionally. So, the idea here is to slow down the game clock enough to maintain a very small queue of waiting tasklets, then when the load clears, raise time back up to normal as we can handle it. This will be done dynamically and in very fine increments; there's no reason we can't run at 98% time if we're just slightly overloaded.
Okay sure, but how do you see it going during a big fight?
Here's how I envision this working for a large engagement (say, 1600 or so). When the attacking fleet warps in, the server gets extremely overloaded - warp-in and other setup tasks like drone deployment are quite expensive - so the game clock gets dilated extremely, down to 5% of real time or something. As those tasks complete, the server gets ahead enough to safely creep the dilation factor up to around 30% of normal time, and the fight is properly joined. At this point, we're sitting with 1600 actively fighting, with their requests being acknowledged quickly and fairly, but everything just taking about 3x as long as usual. The players in the fleet can tell that's happening because many of the HUD elements are animating slowly and the explosions in space are slow-mo too. As more ships die/chicken out, the load of the fight eases up and at around 1200 engaged I'll guesstimate we're back up to around 60% of normal time. Maybe at this point one of the FCs realizes he's boned and calls the retreat. Jumping out is expensive as well, so the clock dilates back down far, to let's say 10%, while the fleet buggers off. With the fighting over and the losers bailed, there's very little load remaining on the server and it returns to 100% time.
There's some tricky design bits in here, of course, like what to do about long timers and the like. I think most of these cases are pretty easy to sort - if we dilate something like reinforce timers, it opens up the ability for players to move when the reinforcement will expire, which goes against the purpose of them. So reinforcement timers cannot dilate. On the flipside, shield recharge is something that can take a while but is critically important to the flow of combat, so that must be dilated. The rule of thumb I'm going with on this is that if you look at your watch to see what time an event is going to complete, it probably shouldn't be dilated. If you can think of a case where that shouldn't apply, please bring it up in the comments thread of this blog.
Expectations management time!
Time dilation does not solve everything. Some load is not tied to a time duration, so we won't be able to handle indefinitely-sized fights. We're at the point today where I think this will cover all of what we see on a regular basis with grace. I do think, however, we'll have to put in a hard limit on how far we're willing to dilate; there's no sense having a system running at .1% time, since no one will be able to do much of anything and it'll just never go anywhere. I don't know where that threshold will be - it'll be something we have to play with after deployment most likely. If fights are regularly going past whatever that threshold is though, we're back to where we are today with the server becoming unresponsive and nasty and stuff. We shall see.
This was a pretty long blog here talking about something that's super-tentative. This has been an idea on my radar for a long time now, but not a whole lot of actual work has gone into it to date. We made a prototype back in August just to prove that the game can handle a dilated clock, and it's been sitting at that stage since. The immensely positive feedback I got after mentioning the idea at Fanfest, combined with the CSM spotlighting it as top of their current wish list convinced me that this is an idea who's time has come. It's a fairly big project though, so I'm comfortable saying you won't see it shipping this summer. Fall's a good possibility if things go well.
tl;dr:
Time dilation slows down time so the server can keep up with what y'all are doing. We're going to work on it nowish and if everything works out you'll see it some time not quite soon.
